![]()
Free 3V0-25.25 Exam Study Guide for the NEW [Apr-2026] Dumps Test Engine
3V0-25.25 PDF Dumps Extremely Quick Way Of Preparation
NEW QUESTION # 24
An administrator has noticed that both the active and standby Global Managers have gone offline.
What is the correct sequence of events to restore the Global Managers?
Answer:
Explanation: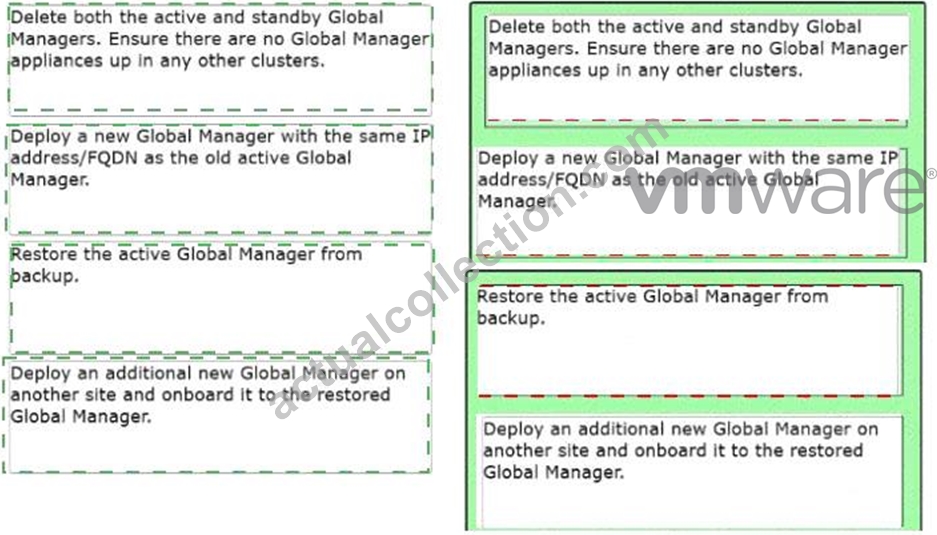
Explanation:
* Step 1: Delete both the active and standby Global Managers. Ensure there are no Global Manager appliances up in any other clusters.
* Step 2: Deploy a new Global Manager with the same IP address/FQDN as the old active Global Manager.
* Step 3: Restore the active Global Manager from backup.
* Step 4: Deploy an additional new Global Manager on another site and onboard it to the restored Global Manager.
In aVMware Cloud Foundationmulti-site deployment usingNSX Federation, the Global Manager (GM) manages the global networking configuration across multiple sites. If the entire GM cluster (Active and Standby) fails, the following architectural principles apply:
* Cleanup (Step 1):Before initiating a restore, the environment must be "cleaned." If old, failed VMs remain in the inventory or on the hosts, they can cause IP address conflicts or UUID mismatches during the deployment of the new appliance. You must ensure the management plane is clear of the original failed nodes.
* Identity Consistency (Step 2):When restoring an NSX appliance (Local or Global) from backup, the new appliancemustbe deployed with the exact sameIP address and FQDNas the original active node.
This is critical because the existing Local Managers (LMs) at each site already have established thumbprints and communication channels tied to that specific identity.
* The Restore Operation (Step 3):Once the "seed" appliance is deployed, the restore process is triggered through the NSX Manager UI/API. This process re-populates the database with the global segments, firewall rules, and Tier-0/Tier-1 configurations.
* Restoring Redundancy (Step 4):The backup only contains the configuration of the cluster. It does not
"restore" the standby VM itself. High Availability (HA) must be manually re-established by deploying a second GM appliance at the secondary site and joining it to the newly restored Global Manager cluster to act as the standby.
NEW QUESTION # 25
An administrator has deployed a new VMware Cloud Foundation (VCF) management domain. To be compliant with company policy, backups must be configured to occur anytime a change is made to the NSX configuration. How can the administrator ensure that complete configuration backups are captured every time a change occurs?
- A. Configure a cron job on the NSX Manager to automatically perform an incremental backup of the NSX configuration every hour.
- B. Configure an alarm to detect configuration changes and automatically trigger a complete configuration backup.
- C. Create a recurring backup schedule and explicitly indicate that backups should be captured anytime the configuration changes.
- D. No action is required as by default NSX will automatically perform a complete backup every time a change is made to the configuration.
Answer: C
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
InVMware Cloud Foundation (VCF), the protection of theNSX Managerconfiguration is paramount, as it contains the state of the entire software-defined network, including firewall rules, logical switches, and routing topologies. To meet strict compliance requirements for real-time or change-based protection, NSX offers specific automated backup triggers.
Within theNSX Manager UI(under System > Lifecycle > Backup & Restore), an administrator can configure the backup behavior. While a time-based schedule (e.g., daily at 2:00 AM) is common, it does not satisfy the requirement for backups "anytime a change is made." To accomplish this, the administrator must enable the
"Backup on Configuration Change"toggle within the backup scheduling configuration.
When this feature is enabled, the NSX Manager monitors its own management database (DS) for write operations. Once a configuration change is detected (such as adding a segment or modifying a DFW rule), the system initiates an automated backup process. This ensures that the backup repository always contains a near- instantaneous reflection of the current network state, minimizing data loss in the event of a cluster failure.
Option B is incorrect because this feature is not enabled by default; it requires an external SFTP/FTP server to be configured first. Option C (Cron jobs) is an unsupported manual workaround that bypasses the SDDC- native management tools. Option A is redundant as the functionality is built directly into the NSX backup engine. Consequently, the verified method for compliance is to use thenative recurring backup schedule with the "Detect Configuration Change" option enabled.
NEW QUESTION # 26
An administrator is tasked to enable users to configure an individual VPC, but not create subnets. What three NSX roles would the administrator assign to allow access without the ability to create subnets? (Choose three.)
- A. Security Operator
- B. VPC Admin
- C. Network Operator
- D. Network Admin
- E. Security Admin
Answer: A,B,C
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
With the introduction of theVirtual Private Cloud (VPC)consumption model inVCF 9.0and late 5.x releases, Role-Based Access Control (RBAC) has become more granular to support true multi-tenancy. A VPC is designed to be a self-contained "container" for a department's or user's networking resources.
To meet the specific requirement where a user can configure aspects of an individual VPC but is restricted from creating new subnets (which involves modifying the underlying network CIDR blocks and IPAM), a combination of specific roles is required.
* VPC Admin:This is the primary role for the user within their assigned VPC. It allows the user to manage the overall VPC environment, including high-level settings and monitoring. However, the VPC Admin's power is often limited by the specific quotas and policies set by the Enterprise Admin.
* Security Operator:This role allows the user to view security configurations and policies without having the permission to modify the network fabric or create new infrastructure components like subnets. It provides the "read-only" visibility into the security posture of the VPC.
* Network Operator:Similar to the Security Operator, the Network Operator role provides visibility into the networking state-such as routing tables, segment status, and connectivity-without granting the
"Write" permissions required to provision new subnets or alter the network topology.
AssigningNetwork Admin(Option B) orSecurity Admin(Option A) would grant too much privilege, as these roles typically include the ability to create, delete, and modify subnets and firewall policies at a structural level. By combining theVPC Adminrole withOperator-level roles, the administrator ensures the user has the necessary context to manage their assigned resources while strictly adhering to the restriction against creating new network subnets.
NEW QUESTION # 27
An administrator is upgrading an existing VMware Cloud Foundation (VCF) environment. An NSX Edge Cluster is required to support north-south traffic for a workload domain. How would the administrator initiate the edge cluster deployment?
- A. From the vCenter Server Appliance Management Interface (VAMI).
- B. From vCenter Network Connectivity wizard.
- C. From the VCF Installer.
- D. Through VCF Operations Fleet Manager.
Answer: D
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
In the architectural framework ofVMware Cloud Foundation (VCF) 9.0, the deployment and lifecycle management of infrastructure components have transitioned into a unified "Fleet Management" model. While previous versions of VCF (like 4.x or 5.x) relied exclusively on the SDDC Manager UI for the deployment of NSX Edge Clusters, VCF 9.0 centralizes these operations withinVCF Operations(integrated with the functionality formerly known as Aria Operations).
To initiate the deployment of an NSX Edge Cluster for a workload domain, the administrator uses theVCF Operations Fleet Manager. This interface provides a centralized orchestration point for the entire VCF
"fleet." When the deployment is triggered here, the system automates the selection of the underlying ESXi hosts, the configuration of the Virtual Distributed Switch (VDS) trunks, and the instantiation of the Edge VM appliances. This ensures that the deployment adheres strictly to theVMware Validated Solutions (VVS) guidelines and is consistent across all domains.
Option A is incorrect because theVCF Installer(Cloud Builder) is used for the initial "Day 0" bring-up of the Management Domain, not for post-deployment additions to workload domains. Option C and D are incorrect asvCenterand theVAMIdo not possess the multi-component awareness or the SDDC-level automation required to configure NSX Edge Clusters in a VCF context. By usingFleet Manager, VCF ensures that the new Edge cluster is automatically integrated into the SDDC Manager's inventory and lifecycle management workflows, maintaining a "single source of truth" for the entire private cloud environment.
NEW QUESTION # 28
An administrator is creating NSX segments in an environment. The NSX segment on an ESX Host is not realized. To troubleshoot the issue, the administrator needs to track the communication of components in the environment.
Drag and drop the component to the appropriate location in the diagram to track the path from desired state to completed state.
Answer:
Explanation: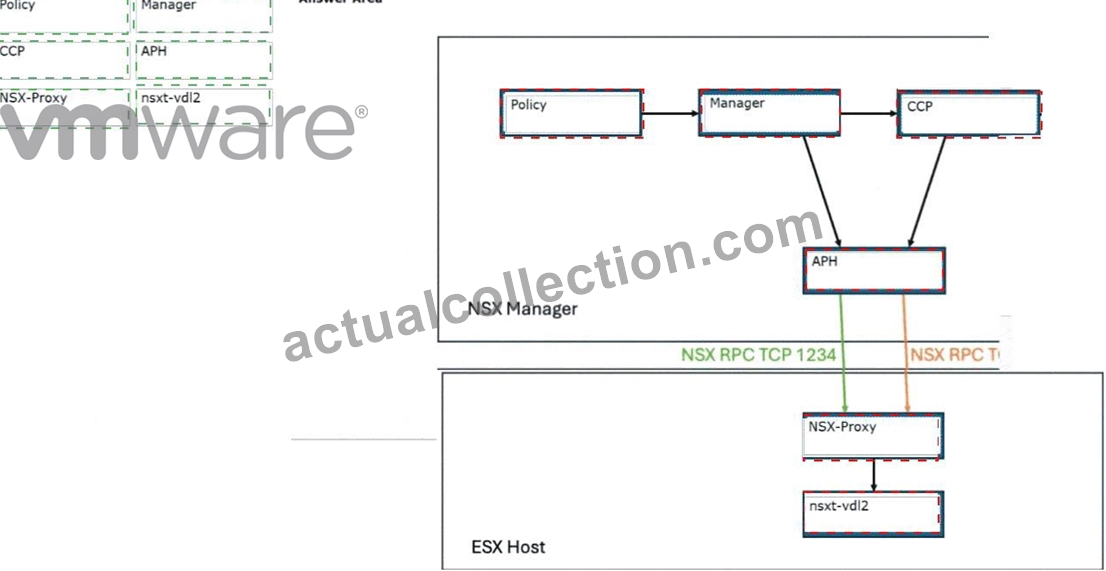
Explanation:
Answer Area Placement:
* NSX Manager Top-Left Box:Policy
* NSX Manager Top-Middle Box:Manager
* NSX Manager Top-Right Box:CCP (Central Control Plane)
* NSX Manager Bottom Box:APH (Asynchronous Proxy Handler)
* ESXi Host Top Box:NSX-Proxy
* ESXi Host Bottom Box:nsxt-vdl2
InVMware Cloud Foundation (VCF)and NSX architectures, the realization of a logical object (like a segment) involves a multi-step communication flow across different management and control plane layers.
The Management Plane (NSX Manager)
* Policy:The entry point where the "Desired State" is defined by the user or automation.
* Manager:Receives the policy, validates it, and stores it in the management database.
* CCP (Central Control Plane):Processes the logical configuration and computes the actual instructions needed for the data plane.
* APH (Asynchronous Proxy Handler):Acts as a broker on the NSX Manager, responsible for pushing these instructions down to the transport nodes viaNSX RPC TCP 1234(Management) andNSX RPC TCP 1235(Control).
The Local Control Plane (ESXi Host)
* NSX-Proxy:A local agent on the ESXi host that maintains a persistent connection to the APH. It receives the instructions and ensures the "Local Control Plane" state matches the "Central Control Plane" intent.
* nsxt-vdl2:The final component in the chain. It interacts directly with the ESXi kernel modules to program the Virtual Distributed Switch (VDS) and realize the segment on the host. Once this step is finished, the segment moves to the"Completed State"and is ready for use.
NEW QUESTION # 29
An administrator is responsible for a VMware Cloud Foundation (VCF) Private Cloud. The administrator has been tasked with identifying why there is no data ingress into a workload domain.
The workload domain has been configured with:
. A dedicated NSX Edge Cluster.
. A Tier 0 gateway.
. A Tier-1 gateway that is configured for Distributed Routing only.
. An NSX segment where a test virtual machine is located.
As part of the exercise, the administrator must map the traffic flow for data ingress into the workload domain to identify the steps that external network traffic will take to ingress into the workload domain and reach the virtual machine.
Drag and drop the six steps from the Steps list on the right and place them in order in the Solution Steps.
(Choose six.)
Answer:
Explanation:
Explanation:
To identify why there is no data ingress into a workload domain, an administrator must understand the specific path external traffic takes. For a workload domain configured with a Tier-0 gateway and a Tier-1 gateway (Distributed Routing only), the ingress traffic flow follows a hierarchical path from the physical network through the NSX logical components to the virtual machine.
Ingress Traffic Flow Sequence
The correct sequence of steps for external network traffic to ingress the workload domain and reach the virtual machine is as follows:
* Uplink for the Tier-0 Service Router (SR): Traffic enters the NSX environment from the physical network through the physical-to-logical interface on the Edge node.
* Inter-Tier interface of the Distributed Router (DR) of the Tier-0 gateway: After being received by the Service Router, the packet is routed internally within the Tier-0 gateway to its distributed component.
* Inter-tier interface of the Distributed Router (DR) on the Tier-1 gateway TEP on the Edge: The Tier-0 gateway routes the packet to the Tier-1 gateway. In this specific scenario, since the Tier-1 is
"Distributed Routing only," this logical transition occurs on the Edge node participating in the transport zone.
* TEP on the destination host: The Edge node encapsulates the packet (typically via Geneve) and tunnels it across the physical fabric to the specific ESXi host where the target virtual machine is currently residing.
* Downlink interface of the Tier-1 Distributed Router (DR) to the segment to which the workload VM is attached: On the destination host, the packet is de-encapsulated. The local Tier-1 DR instance identifies the correct logical segment (VNI) for the destination IP.
* NSX portgroup representing the destination segment on the destination host dvfilter and vNic of the workload VM: The packet is delivered to the virtual switch port, passes through any applied Distributed Firewall (dvfilter) rules, and finally reaches the virtual machine's network interface card (vNIC).
NEW QUESTION # 30
An administrator is troubleshooting BGP flapping in a VMware Cloud Foundation (VCF) 9 environment. A Tier-0 Gateway is running in Active/Active mode with two Edge nodes. BFD is enabled on the eBGP sessions to the upstream routers. Each Edge node uses its own uplink IP for BGP. After some network maintenance, one BGP session starts flapping every few minutes. The other BGP sessions stay stable. On the affected Edge node, the command get bfd-sessions shows:
* State: Down
* Diag: Detect Time Expired
Symptoms:
* The upstream router also shows the BFD session as Down with control Detection Time Expired.
* There are no interface errors, no packet loss for normal traffic, and clearing the BFD session temporarily brings it back up - but it flaps again after few minutes.
What is the root cause?
- A. The MTU does not match on the end-to-end between Tier-0 Gateway and upstream routers.
- B. BFD timers are mismatched between Tier-0 Gateway and the upstream routers.
- C. The Edge nodes are undersized and are experiencing high contention on CPU and drops BFD packets.
- D. BFD is configured in echo mode on the upstream routers.
Answer: A
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
In aVMware Cloud Foundation (VCF)environment, particularly with the high-performance requirements of North-South routing,BGPandBFD (Bidirectional Forwarding Detection)are used in tandem to ensure rapid failure detection. A common but subtle issue in fresh or modified environments is anMTU (Maximum Transmission Unit) mismatchon the physical or virtual uplinks.
When BGP establishes a neighborship, it initially exchanges small keepalive packets. These small packets easily pass through interfaces even if there is an MTU mismatch (e.g., the Edge is set to 9000 bytes but a physical switch in the path is limited to 1500 bytes). However, once the BGP state reaches "Established," the routers begin exchanging full routing tables. TheseBGP Updatepackets are often large and will be fragmented or dropped if they exceed the MTU of any hop in the path.
The symptom described-where the session is stable for a few minutes (during the initial handshake) and then flaps-is the hallmark of an MTU issue. The "Detect Time Expired" diagnostic in BFD occurs because the BGP hold timer expires when it fails to receive the large update packets, or the BFD packets themselves are delayed/lost due to the congestion caused by retrying large, failed transmissions. According to VMware NSX troubleshooting documentation, if pings (small packets) succeed but the BGP session fails specifically when traffic load or route counts increase, the MTU should be the first setting verified.
VCF 9.0 and 5.x designs mandate consistent MTU settings (typically9000 MTUfor the overlay and at least
1500+for the uplinks) across the entire path, including the virtual switch (VDS), the Edge VM vNICs, and the physical ToR switches. A mismatch here prevents the completion of the BGP state machine's full synchronization, leading to the cyclic "flapping" observed by the administrator.
NEW QUESTION # 31
A sovereign cloud provider has a VMware Cloud Foundation (VCF) stretched Workload Domain across two data centers (AZ1 and AZ2), where site connectivity via Layer 3 is provided by the underlay. The following NSX details are included in the design:
* Each site must host its own local NSX Edge Cluster for availability zones.
* Tier-0 gateways must be configured in active/active mode with BGP ECMP to local top-of-rack switches.
* Inter-site Edge TEP traffic must not cross the inter-DC link.
* SDDC Manager is used to automate NSX deployment.
During deployment of the Edge Cluster for AZ2, the SDDC Manager workflow fails because the Edge transport nodes' TEP IPs are not reachable from the ESXi transport nodes. Which step ensures correct Edge Cluster deployment in multi-site stretched domains?
- A. Disable the liveness check during Edge deployment in SDDC Manager.
- B. Create an AZ2-specific Edge TEP IP pool and map it to the AZ2 uplink profile before deploying the Edge Cluster.
- C. Reuse the TEP IP pool from AZ1.
- D. Configure BGP neighbors before deploying the Edge Cluster.
Answer: B
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
In aVMware Cloud Foundation (VCF)stretched cluster or Multi-Availability Zone (Multi-AZ) architecture, the networking design must account for the fact that AZ1 and AZ2 typically reside in different Layer 3 subnets. While the NSX Overlay provides Layer 2 adjacency for virtual machines across sites, the underlying Tunnel Endpoints (TEPs)must be able to communicate over the physical Layer 3 network.
According to the VCF Design Guide for Multi-AZ deployments, when stretching a workload domain, each availability zone should have its own dedicatedTEP IP Pool. This is because TEP traffic is encapsulated (Geneve) and routed via the physical underlay. If the Edge nodes in AZ2 were to use the same IP pool as AZ1 (Option C), the physical routers would likely encounter routing conflicts or reachability issues, as the subnet for AZ1 would not be natively routable or "local" to the AZ2 Top-of-Rack (ToR) switches.
The failure during the SDDC Manager workflow occurs because the automated "Liveness Check" or "Pre- validation" step attempts to verify that the newly assigned TEP IPs in AZ2 can reach the existing TEPs in the environment. To resolve this and ensure a successful deployment, the administrator must define a uniqueAZ2- specific IP Poolin NSX. Furthermore, this pool must be associated with anUplink Profile(or a Sub-Transport Node Profile in VCF 5.x/9.0) that uses the specific VLAN tagged for TEP traffic in the second data center.
This ensures that the Edge Nodes in AZ2 are assigned IPs that are valid and routable within the AZ2 underlay, allowing Geneve tunnels to establish correctly to the ESXi hosts in both sites without requiring a stretched Layer 2 physical network for the TEP infrastructure.
NEW QUESTION # 32
The administrator is implementing a multi-location VMware Cloud Foundation (VCF) environment. The design requires centralized security and networking policies across multiple VCF instances. What action must the administrator take to satisfy the requirements?
- A. Use SDDC Manager to deploy a Global Manager cluster.
- B. Use VCF Installer to deploy a Local Manager (LM) cluster.
- C. Deploy a Global Manager cluster manually.
- D. Deploy a Local Manager (LM) cluster using VCF Operations.
Answer: A
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
In aVMware Cloud Foundation (VCF)Multi-Site or Multi-Instance design, the requirement for "centralized security and networking policies" is fulfilled byNSX Federation. Federation introduces theGlobal Manager (GM), which provides a single pane of glass to manage objects that span across different VCF sites.
Historically, in early versions of NSX-T, Global Managers were deployed manually. However, within the VCF framework (VCF 4.x, 5.x, and 9.0), the deployment and lifecycle management of theGlobal Manager clusterare fully integrated intoSDDC Manager. According to the VCF Design Guide and "Deploying and Configuring NSX Federation" documents, the verified best practice is to use the SDDC Manager UI or API to trigger the GM deployment.
When an administrator usesSDDC Manager(Option C), the process is automated: SDDC Manager deploys the appliances, configures the virtual IP (VIP), handles the certificate management, and ensures that the GM is properly integrated into the VCF Bill of Materials (BOM). This automation is critical for maintaining supportability, as it ensures the GM version is perfectly aligned with the Local Managers (LMs) already present in the Management and Workload domains.
Option A is discouraged because manual deployments lead to configuration drift and issues with future automated upgrades. Option B is incorrect as VCF Operations is for monitoring, not deployment. Option D is incorrect because theVCF Installeris primarily used for the initial "bring-up" of the Management Domain; subsequent management components like GMs are handled by the SDDC Manager once the initial site is active. Thus, SDDC Manager is the authoritative tool for deploying the Global Manager cluster in a VCF multi-location environment.
NEW QUESTION # 33
An administrator has observed an NSX Local Manager (LM) outage at the secondary Site. However, the NSX Global Manager (GM) in secondary Site remains operational. What happens to data plane operations and policy enforcement at the secondary site?
- A. Only local policies work; global policies cease to apply on the secondary site.
- B. Secondary site must failover all workloads to Primary site.
- C. All traffic is blocked until secondary site LM recovers.
- D. The data plane operates normally until LM recovery and reconnection.
Answer: D
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
The architecture ofNSX Federationwithin a VCF Multi-Site design is built upon a separation of theControl Planeand theData Plane. This "decoupled" architecture ensures high availability and resiliency even when management components become unavailable.
In NSX Federation, theGlobal Manager (GM)handles the configuration of objects that span multiple locations, while theLocal Manager (LM)is responsible for pushing those configurations down to the local Transport Nodes (ESXi hosts and Edges) within its specific site. When a configuration is pushed, the Local Manager communicates with theCentral Control Plane (CCP)and subsequently theLocal Control Plane (LCP)on the hosts.
If an NSX Local Manager goes offline, the "Management Plane" for that site is lost. This means no new segments, routers, or firewall rules can be created or modified at that site. However, the existing configuration is already programmed into theData Plane(the kernels of the ESXi hosts and the DPDK process of the Edge nodes).
According to VMware's "NSX Multi-Location Design Guide," the data plane remains fully operational during a Management Plane outage. Existing VMs will continue to communicate, BGP sessions on the Edges will remain established, and Distributed Firewall (DFW) rules will continue to be enforced based on the last known good configuration state cached on the hosts. The data plane does not require constant heartbeats from the Local Manager to forward traffic. Therefore, operations continue normally "headless" until the LM is restored and can resume synchronization with the Global Manager and local hosts. Failover to a primary site (Option D) is only necessary if the actual data plane (hosts/storage) fails, not just the management components.
NEW QUESTION # 34
During a design review, the administrator is asked to explain which underlying technology enables the NSX Edge to perform fast packet processing and achieve near line-rate performance for Virtual Network Functions (VNFs). Which technology is leveraged in the NSX Edge for fast packet processing?
- A. AMD Power Now
- B. Intel Speed Step
- C. Data Plane Development Kit (DPDK)
- D. Non-Uniform Memory Access (NUMA)
Answer: C
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
TheNSX Edgeis the workhorse of the VMware Cloud Foundation networking stack, handling demanding tasks like Geneve encapsulation, NAT, Firewalling, and BGP routing. To achieve the throughput required for modern data centers-often exceeding 10Gbps or even 40Gbps per node-NSX leverages theData Plane Development Kit (DPDK).
Traditional packet processing in a standard Linux or Unix kernel is often a bottleneck. The kernel must handle interrupts, context switching between user space and kernel space, and complex buffer management for every packet. This "overhead" limits the speed at which a CPU can move packets.DPDKchanges this by bypassing the standard kernel networking stack entirely. It operates inUser Spaceand uses a "polling" mechanism rather than an "interrupt-driven" one.
In an NSX Edge VM or Bare Metal node, specific CPU cores are dedicated to the DPDK process (often called theDatapathorFP-Main). these cores "spin" at 100% utilization, constantly checking the NICs for new packets. Because there is no context switching and the process has direct access to the network hardware buffers, the Edge can process millions of packets per second (Mpps) with extremely low latency.
WhileNUMA(Option C) is a hardware architecture that NSX is "aware" of to optimize memory access, and Intel Speed Step/AMD Power Now (Options B and D) are power management features,DPDKis the actual software technology that enables the "fast packet processing" capability of the VCF networking solution. This is why VMware documentation emphasizes the importance of ensuring that Edge VMs are sized correctly with enough "High-Performance" cores to support the intended DPDK throughput.
NEW QUESTION # 35
An administrator changed the SFTP server used for scheduled NSX Manager backups. The backup jobs now fail with the error "Host KEY Verification Failed." The connectivity and credentials are correct. How would an administrator resolve the error?
- A. Trust the certificate on the SFTP server.
- B. Use the NSX cluster VIP as the SFTP endpoint.
- C. Turn Off Backup encryption.
- D. Update the SSH fingerprint.
Answer: D
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
InVMware Cloud Foundation (VCF), theNSX Manageruses the SFTP protocol to securely transfer configuration backups to an external repository. SFTP is built on top of the SSH protocol, which relies on a
"Trust on First Use" (TOFU) model for verifying the identity of the remote host.
When an NSX Manager first connects to an SFTP server, it retrieves the server'sSSH Public Key Fingerprint and stores it in its local known_hosts equivalent database. This fingerprint ensures that future connections are made to the same, verified server, preventing man-in-the-middle attacks.
The error"Host KEY Verification Failed"occurs when the administrator changes the SFTP server (or if the SFTP server's OS was reinstalled/keys regenerated). Even if the IP address remains the same, the new server presents a different SSH fingerprint than the one currently cached in the NSX Manager configuration.
Because the signatures do not match, the NSX Manager aborts the connection for security reasons.
To resolve this issue, the administrator mustUpdate the SSH fingerprint(Option B) within the NSX Manager backup settings. This involves:
* Retrieving the new fingerprint from the SFTP server (e.g., via ssh-keyscan).
* Navigating to System > Lifecycle > Backup & Restore in the NSX Manager.
* Editing the File Server configuration and pasting the new fingerprint into the appropriate field.
Option A is incorrect as it does not address the SSH protocol handshake failure. Option C is incorrect because SFTP/SSH uses fingerprints, not SSL/TLS certificates. Option D is irrelevant as it changes the source
/destination of the connection but does not fix the underlying trust mismatch. Therefore, updating the fingerprint is the verified operational step to restore the automated backup workflow in VCF.
NEW QUESTION # 36
An administrator is troubleshooting a BGP connectivity issue on a Tier-0 Gateway (Active/Active). The Tier-
0 has the following configuration:
* Uplink VLAN 100: 192.168.100.0/24
* Uplink VLAN 101: 192.168.101.0/24
* BGP neighbors configured: 192.168.100.1 and 192.168.101.1
* A single static default route (0.0.0.0/0) exists with next-hop 192.168.100.1.
Symptoms observed on both Edge Nodes:
* Get BGP neighbors -> both neighbors stuck in Idle (Connect) - "No route to peer"
* Ping to 192.168.100.1 and 192.168.101.1 succeeds from the Edge nodes
* Get route shows the default route present only on VLAN 100 interface (fp-eth0), missing on VLAN 101 (fp- eth1) What is the root cause of both BGP sessions remaining in Idle state?
- A. The static default route Scope is set only to the uplink VLAN 100 segment.
- B. The ToR routers do not have routes back to the Edge uplink interfaces.
- C. Multi-hop eBGP is required when using two VLANs.
- D. BGP authentication mismatch between Tier-0 and ToR routers.
Answer: A
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
InVMware NSXnetworking, the Tier-0 Gateway'sRouting Table(RIB) is the definitive source for determining how to reach BGP neighbors. A common point of confusion occurs when an administrator can
"ping" a neighbor but the BGP state remainsIdleorConnectwith a "No route to peer" error.
This symptom specifically points to the"Scope"setting of a static route. In NSX, when a static route (such as the default route 0.0.0.0/0) is created, the administrator can define theScopeto be a specific uplink segment or interface. If the scope is set exclusively to theVLAN 100segment, the Tier-0 Gateway will only install that route into the forwarding table for the Service Router (SR) component associated with the VLAN 100 interface.
Because the default route is the only path the Tier-0 has to reach non-local networks (or even other local subnets not directly attached), the BGP process for the neighbor at192.168.101.1(VLAN 101) checks the routing table for a path. Since the only available route is scoped strictly to VLAN 100, the Tier-0 determines it has "No route" to reach the neighbor in VLAN 101. BGP requires a valid entry in the routing table for the neighbor's IP before it will even attempt to initiate the TCP three-way handshake on port 179.
The fact that pings succeed is due to pings often being tested from the specific interface (e.g., ping
192.168.101.1 -I fp-eth1), which bypasses the general routing table logic that the BGP control plane must follow. To resolve this, the static route scope should be expanded to include all relevant uplink segments or left as "All Uplinks," ensuring that the Tier-0 recognizes valid egress paths for neighbors on both VLAN 100 and VLAN 101.
NEW QUESTION # 37
An administrator must prevent a new VPC from exporting any of its prefixes to the datacenter while still receiving a default route. Where should the routing policy be applied?
- A. On the VPC's Transit Gateway
- B. On the VPC default route advertiser
- C. On the providers' BGP peer template
- D. On the VPC Gateway Firewall
Answer: A
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
In the advanced networking architecture ofVMware Cloud Foundation (VCF) 9.0and the evolution ofNSX VPCs, the control of route propagation is managed through the relationship between the consumer (the VPC) and the provider (the Tier-0 or Tier-1 Gateway). When a VPC is created, it is logically connected to the provider's infrastructure via aTransit Gateway(or a Provider-side logical router acting as a transit point).
To control the flow of routing information-specifically to prevent the data center's physical network from learning about internal VPC subnets (prefixes) while ensuring the VPC can still reach the outside world via a default route-the routing policy must be applied at the point of intersection. TheTransit Gatewayserves as this demarcation point. By applying a route filter or prefix list on the Transit Gateway, the administrator can explicitly deny the advertisement of internal VPC prefixes "upstream" to the provider's BGP process.
Simultaneously, the provider can still inject or "advertise" a default route ($0.0.0.0/0$) "downstream" into the VPC.
Applying the policy on theVPC Gateway Firewall(Option D) would impact the data plane (blocking traffic) but would not prevent the routing table from being populated. TheBGP peer template(Option C) is too broad, as it would likely affect all VPCs connected to that provider, rather than just the "new VPC" in question. Thedefault route advertiser(Option A) only controls the egress of the default route, not the suppression of internal prefixes. Therefore, the Transit Gateway is the verified location for granular route control in a multi-tenant VCF VPC environment.
NEW QUESTION # 38
The administrator is working to ascertain the encapsulation of GENEVE by reviewing the capture on Wireshark.
The administrator instructed VM-1 to send a continuous ICMP request directed at VM-2.
Click to highlight where the administrator should observe the GENEVE encapsulated packet.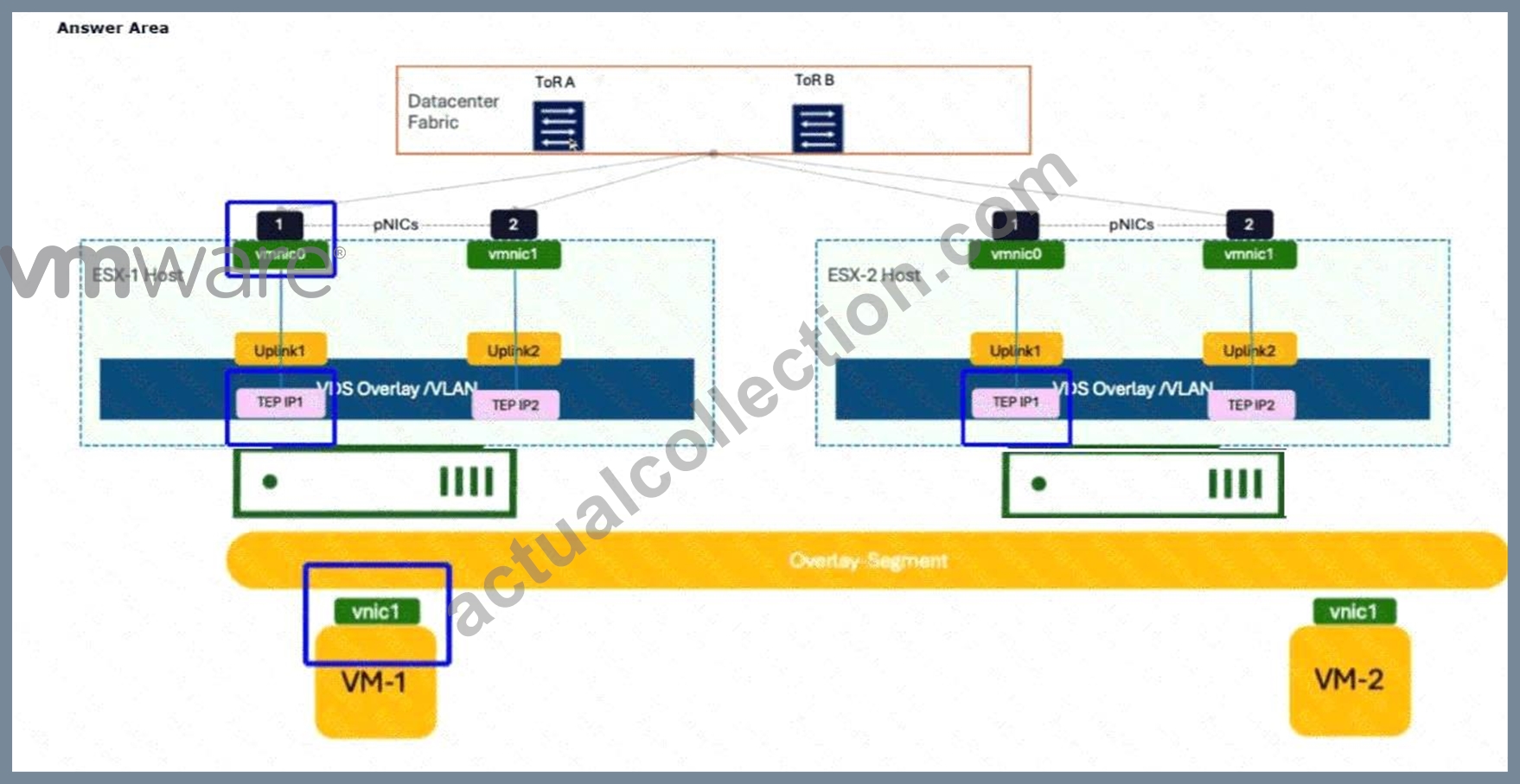
Answer:
Explanation: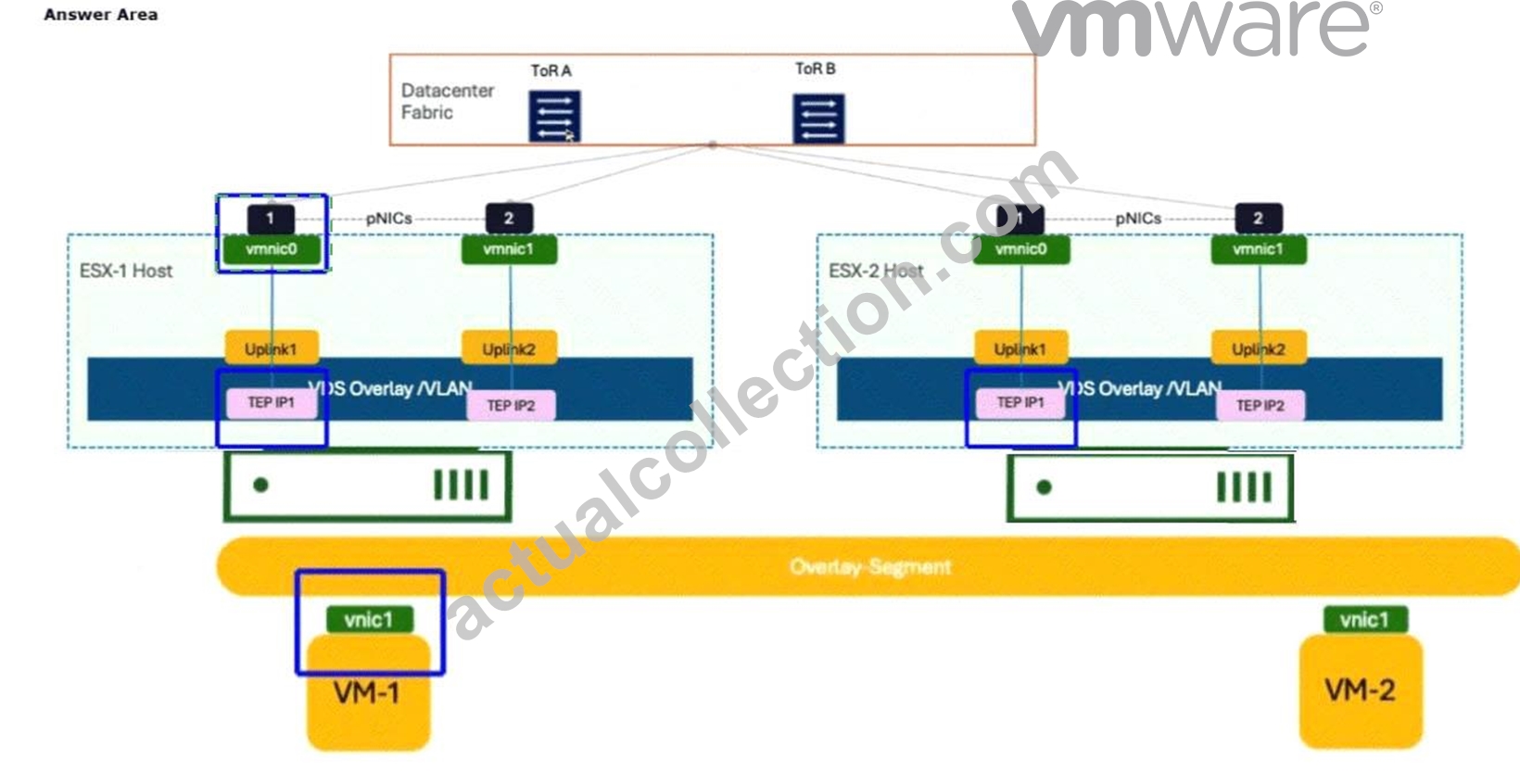
Explanation:
The administrator should click thevmnic0interface on theESX-1 Host.
In aVMware Cloud Foundation (VCF)environment, theGENEVE (Generic Network Virtualization Encapsulation)protocol is the industry-standard tunnel format used by NSX to create an overlay network.
This protocol allows Layer 2 traffic from virtual machines to be "tunneled" over a Layer 3 physical IP fabric, enabling workloads to communicate as if they were on the same segment even when separated by physical routers.
When VM-1 on ESX-1 sends an ICMP request to VM-2 on ESX-2, the packet starts as a standard Ethernet frame at the virtual machine'svnic1. At this stage, the packet contains no encapsulation. As the frame enters theVirtual Distributed Switch (VDS)and hits theTunnel End Point (TEP), the host's kernel performs the encapsulation process. The TEP adds a GENEVE header, a UDP header (port 6081), and an outer IP header.
Thevmnic0(physical NIC) on the source host (ESX-1) is the specific "egress" point where this transformation is complete. A packet capture taken at this physical interface will show the "Outer IP" address of the source TEP and destination TEP, with the original ICMP packet hidden inside the GENEVE payload. If the administrator were to click on the VM's vnic, they would only see standard ICMP. By selecting thevmnic0, the administrator captures the traffic as it is placed onto the physical wire, which is the verified location to troubleshoot MTU issues, encapsulation errors, or physical fabric connectivity in a VCF environment.
NEW QUESTION # 39
An architect needs to allow users to deploy multiple copies of a test lab with public access to the internet. The design requires the same machine IPs be used for each deployment. What configuration will allow each lab to connect to the public internet?
- A. Configure SNAT rules on the Tier-0 gateway.
- B. Configure isolation on the NSX segment.
- C. Configure firewall rules to isolate the traffic going to the public internet.
- D. Configure DNAT rules on the Tier-1 gateway.
Answer: A
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
This scenario describes a classic "Overlapping IP" or "Fenced Network" challenge in a private cloud environment. In many development or lab use cases, users need to deploy identical environments where the internal IP addresses (e.g., 192.168.1.10) are the same across different instances to ensure application consistency.
To allow these identical environments to access the public internet simultaneously without causing an IP conflict on the external physical network,Source Network Address Translation (SNAT)is required.
According to VCF and NSX design best practices, theTier-0 Gatewayis the most appropriate place for this translation when multiple tenants or labs need to share a common pool of external/public IP addresses.
When a VM in Lab A sends traffic to the internet, the Tier-0 Gateway intercepts the packet and replaces the internal source IP with a unique public IP (or a shared public IP with different source ports). When Lab B (which uses the same internal IP) sends traffic, the Tier-0 Gateway translates it to adifferentunique public IP (or the same shared public IP with different ports). This ensures that return traffic from the internet can be correctly routed back to the specific lab instance that initiated the request.
Option A (DNAT) is used for inbound traffic (allowing the internet to reach the lab), which doesn't solve the outbound connectivity requirement for overlapping IPs. Option B (Isolation) would prevent communication entirely. Option C (Firewall) controls access but does not solve the routing conflict caused by identical IP addresses. Thus,SNAT rules on the Tier-0 gatewayare the verified solution for providing internet access to overlapping lab environments.
NEW QUESTION # 40
An administrator is tasked to enable users to configure an individual VPC, but not create subnets. What three NSX roles would the administrator assign to allow access without the ability to create subnets? (Choose three.)
- A. Security Operator
- B. VPC Admin
- C. Network Operator
- D. Network Admin
- E. Security Admin
Answer: A,B,C
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
With the introduction of theVirtual Private Cloud (VPC)consumption model inVCF 9.0and late 5.x releases, Role-Based Access Control (RBAC) has become more granular to support true multi-tenancy. A VPC is designed to be a self-contained "container" for a department's or user's networking resources.
To meet the specific requirement where a user can configure aspects of an individual VPC but is restricted from creating new subnets (which involves modifying the underlying network CIDR blocks and IPAM), a combination of specific roles is required.
* VPC Admin:This is the primary role for the user within their assigned VPC. It allows the user to manage the overall VPC environment, including high-level settings and monitoring. However, the VPC Admin's power is often limited by the specific quotas and policies set by the Enterprise Admin.
* Security Operator:This role allows the user to view security configurations and policies without having the permission to modify the network fabric or create new infrastructure components like subnets. It provides the "read-only" visibility into the security posture of the VPC.
* Network Operator:Similar to the Security Operator, the Network Operator role provides visibility into the networking state-such as routing tables, segment status, and connectivity-without granting the
"Write" permissions required to provision new subnets or alter the network topology.
AssigningNetwork Admin(Option B) orSecurity Admin(Option A) would grant too much privilege, as these roles typically include the ability to create, delete, and modify subnets and firewall policies at a structural level. By combining theVPC Adminrole withOperator-level roles, the administrator ensures the user has the necessary context to manage their assigned resources while strictly adhering to the restriction against creating new network subnets.
NEW QUESTION # 41
When using a DHCP Relay on a segment, which design restriction must be considered?
- A. DHCP settings, DHCP options, and static bindings can be configured on the segment.
- B. DHCP Relay service is available to all the other segments in the network.
- C. DHCP settings, DHCP options, and static bindings cannot be configured on the segment.
- D. DHCP client requests cannot be relayed to the external DHCP servers.
Answer: C
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
InVMware Cloud Foundation (VCF)networking, IP address management within an NSX segment can be handled by either the native NSX DHCP server or by an external DHCP server. When an administrator chooses to use an existing external corporate DHCP infrastructure, they must configure aDHCP Relayon the logical segment.
The DHCP Relay works by intercepting the initial DHCP Discover broadcast from a workload VM and forwarding it (as a unicast packet) to the specified IP address of the external DHCP server. However, NSX enforces a strict mutual exclusivity in its configuration logic to prevent conflicts and unpredictable address assignments.
According to the "NSX-T Data Center Administration Guide," once a segment is configured to use aDHCP Relay profile, the native NSX DHCP capabilities for that specific segment are disabled. This means that DHCP settings, DHCP options, and static bindings cannot be configured on that segment(Option A). All such configurations, including IP reservations and scope options (like DNS or NTP), must be managed centrally on the external DHCP server.
Option C is incorrect because the UI will physically grey out or prevent the entry of native DHCP parameters once the Relay is selected. Option B is incorrect as the primary purpose of a Relay is precisely to forward requests to external servers. Option D is incorrect because a DHCP Relay is configured on a per-segment or per-gateway basis; it is not a "global" service that automatically covers all other segments in the network.
Therefore, the architectural trade-off when choosing a Relay is the shift of all management and binding logic to the external physical or virtual DHCP appliance.
NEW QUESTION # 42
An administrator has observed an NSX Local Manager (LM) outage at the secondary Site. However, the NSX Global Manager (GM) in secondary Site remains operational. What happens to data plane operations and policy enforcement at the secondary site?
- A. Only local policies work; global policies cease to apply on the secondary site.
- B. Secondary site must failover all workloads to Primary site.
- C. All traffic is blocked until secondary site LM recovers.
- D. The data plane operates normally until LM recovery and reconnection.
Answer: D
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
The architecture ofNSX Federationwithin a VCF Multi-Site design is built upon a separation of theControl Planeand theData Plane. This "decoupled" architecture ensures high availability and resiliency even when management components become unavailable.
In NSX Federation, theGlobal Manager (GM)handles the configuration of objects that span multiple locations, while theLocal Manager (LM)is responsible for pushing those configurations down to the local Transport Nodes (ESXi hosts and Edges) within its specific site. When a configuration is pushed, the Local Manager communicates with theCentral Control Plane (CCP)and subsequently theLocal Control Plane (LCP)on the hosts.
If an NSX Local Manager goes offline, the "Management Plane" for that site is lost. This means no new segments, routers, or firewall rules can be created or modified at that site. However, the existing configuration is already programmed into theData Plane(the kernels of the ESXi hosts and the DPDK process of the Edge nodes).
According to VMware's "NSX Multi-Location Design Guide," the data plane remains fully operational during a Management Plane outage. Existing VMs will continue to communicate, BGP sessions on the Edges will remain established, and Distributed Firewall (DFW) rules will continue to be enforced based on the last known good configuration state cached on the hosts. The data plane does not require constant heartbeats from the Local Manager to forward traffic. Therefore, operations continue normally "headless" until the LM is restored and can resume synchronization with the Global Manager and local hosts. Failover to a primary site (Option D) is only necessary if the actual data plane (hosts/storage) fails, not just the management components.
NEW QUESTION # 43
An administrator must provide North/South connectivity for a VPC. The fabric exposes a distributed external VLAN across all ESX hosts. But, the only BGP peer to the core is on a VLAN only accessible on the Edge Cluster. Which design is required?
- A. Use a VPC Tier-0 Gateway in active/active mode with distributed eBGP peering.
- B. Deploy a Provider Tier-1 with BGP and connect the VPC Transit Gateway via route leaking.
- C. Centralized Transit Gateway on the Edge Cluster.
- D. Distributed Transit Gateway with an EVPN route reflector on the transport nodes.
Answer: C
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
In aVMware Cloud Foundation (VCF)environment utilizing theVirtual Private Cloud (VPC)model, North
/South connectivity is managed by theTransit Gateway (TGW). The TGW acts as the bridge between the VPC-internal networks and the provider-level physical network.
The scenario presents a specific constraint: while an external VLAN exists across all hosts, the actual BGP peering point (the interface to the physical core routers) is restricted to theNSX Edge Cluster. In NSX terminology, when a gateway or service must be anchored to specific Edge Nodes to access physical network services-such as BGP peering, NAT, or stateful firewalls-it must be configured as aCentralizedcomponent.
ACentralized Transit Gateway(Option C) is instantiated on the Edge nodes. This allows the TGW to participate in the BGP session with the core routers on the VLAN that is only accessible to those Edges. The TGW then handles the routing for the VPC's internal segments. Traffic from the ESXi transport nodes (East- West) travels via the Geneve overlay to the Edge nodes, where it is then routed North-South by the Centralized TGW using the physical BGP peer.
Option A is incorrect because "distributed eBGP peering" would require every ESXi host to have peering capabilities, which contradicts the constraint. Option B involves EVPN, which is a significantly more complex and different architecture than what is required for standard VPC North/South access. Option D is an unnecessarily complex routing design that is not the standard VCF/VPC implementation pattern. Thus, the use of a Centralized Transit Gateway on the Edge cluster is the verified design requirement to bridge the gap between the overlay VPC and the localized BGP peering point.
NEW QUESTION # 44
When attempting to deploy or expand an edge cluster from an administrator encounters a failure: "Failed to validate the BGP Route Distribution". Prior to calling support, the administrator attempts to troubleshoot the issue. How should the administrator troubleshoot this issue?
- A. Log into the Tier-1 router to verify that route distribution is being enabled.
- B. Log into the vCenter and verify there are no errors or warnings from the NSX manager.
- C. Log into the edge node of the Tier-0 being deployed and check the routes being learnt.
- D. Log into the NSX manager and examine the nsxapi.log for errors.
Answer: C
Explanation:
Comprehensive and Detailed 250 to 350 words of Explanation From VMware Cloud Foundation (VCF) documents:
InVMware Cloud Foundation (VCF), theSDDC Managerautomates the deployment and expansion ofNSX Edge Clusters. As part of the automated workflow, particularly in VCF 4.x, 5.x, and 9.0, a "Verify BGP Route Distribution" task is executed. This task is a validation check designed to ensure that the newly deployed or expanded Edge nodes are successfully peering with the physical Top-of-Rack (ToR) switches and, more importantly, are actually receiving routes.
According to VMware/Broadcom technical documentation (specificallyKB 388351), the workflow expects to see at least one route (often the default route or specific physical prefixes) learned via BGP from the northbound peer. If the Edge nodes establish a BGP session but the physical switches are not advertising any routes (or are only advertising routes that the Edge ignores due to filters), the SDDC Manager validation fails with the error "Failed to validate the BGP Route Distribution".
The verified troubleshooting step is tolog into the CLI of the Edge nodeidentified in the failure. Using the command get route bgp from within the Tier-0 Service Router (SR) VRF context allows the administrator to see the current Routing Information Base (RIB). If the table is empty or only contains internal "ISR" (Inter- SR) routes, it confirms that the physical network is not providing the expected advertisements. This allows the administrator to correct the BGP advertisement settings on the physical ToR switches-such as enabling default-originate-and then simply "Resume" the task in SDDC Manager without needing to redeploy the entire cluster.
NEW QUESTION # 45
......
VMware 3V0-25.25 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
Enhance your career with 3V0-25.25 PDF Dumps - True VMware Exam Questions: https://quizguide.actualcollection.com/3V0-25.25-exam-questions.html